BrainBug - 2026
Da ich für mein Home Assistant und die verbundenen Voice Assistenten gerne eine
lokale Ki nutzen wollte, ist dieses Projekt entstanden.
Als Basis Computer dient mir ein NVIDIA Jetson Nano (Super) mit 8GB dediziertem Speicher.
Natürlich ist meine Version nicht bloß die nackte Platine, welche von einer TF-Speicherkarte gebootet wird. Ich habe mir die Mühe gemacht den NANO mit einer 1TB NVMe auszurüsten und diese bootfähig zu machen.
Der Aufbau einer Ki mit nur 8GB ist gelinde gesagt eine sportliche Herausforderung!
Ich setze daher auf die neuen 1Bit Modelle die jetzt gerade erscheinen
und eine phänomenale Performance bei geringstem VRAM-Bedarf realisieren !!!
Daher kann ich auch nur empfehlen die ersten Gehversuche mit einer TF-Speicherkarte mit einer Größe ab 64GB zu beginnen! Da die Speicherkarte einfacher wieder herzustellen ist als eine NVMe.
Bei mir hat es 8 Versuche gebraucht, bis ich eine Brauchbare Lösung hatte.
Ich habe zunächst verschiedene LLM-Modelle ausprobiert, bin aber immer wieder an der Sprachbarriere gescheitert. Gerne hätte ich einfach eine “unzensierte“ Version verwendet, da diese nicht erst jede Anfrage durch ihre Sicherheitsfilter überprüfen muss. Die Leute verstehen scheinbar nicht wirklich wieviel Zeit für diesen Mist verlorengeht und wie groß der extra Rechenaufwand für eine Nanni-Funktion ist! leider gibt es aber nicht viele Modelle die sich gut für die Home Assistant Integration eignen, unzensiert sind und Deutsch sprechen…
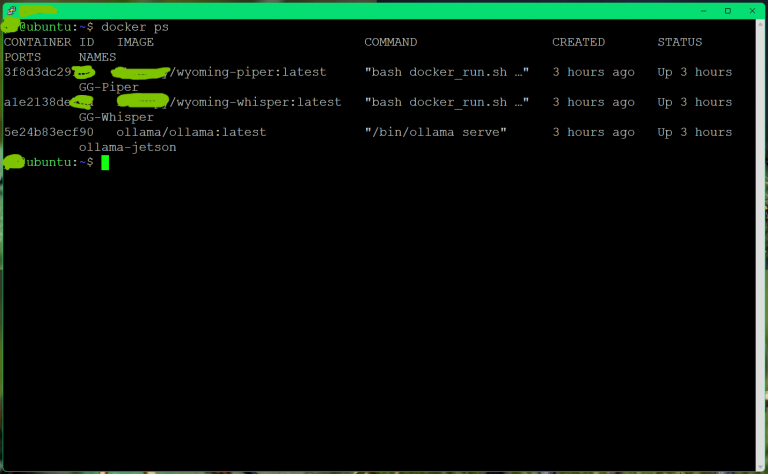
Der momentane Stand bei meinem Gerät ist Ollama3.2:3b + STT & TTS in einem Docker Container.
Die Open WebUi habe ich zu Gunsten von AnythingLLM wieder abgeschaltet, genau wie den blöden Desktop da ich mir so den extra Container und Speicher sparen kann.
Ich brauche für Änderungen und die Überwachung bloß eine SSH-Verbindung, wenn das nicht reicht habe ich ein Skript, das mir einen remote Desktop ermöglicht, das reicht völlig aus – vertraut mir…. 😊
Natürlich werde ich diesen Beitrag mit weiteren Bildern und später auch einer Anleitung zum nachbauen erweitern.
Ich bitte nur um etwas Geduld, da ich noch immer alles mit verschiedenen LLM’s teste…
UPDATE:
Derzeit nutze ich TTS & STT über einen Whisper Container ebenfalls auf dem Nano, um die schlechte Verarbeitung durch die Nabu Casa Cloud systemisch zu entkoppeln…
Ich mag zwar kein HA-Bashing betreiben,….
aber die Verwendung von TTS & STT über die Nabu Casa Cloud führt in der Regel dazu, dass mein Voice Assistent abstürzt und dabei diese Fehlermeldung als Dauerschleife bringt:
The announcement pipeline’s file reader encountered an error.
01:50:41 [E] [speaker_media_player.pipeline:117]
Media reader encountered an error: ESP_FAIL
01:50:41 [E] [speaker_media_player:362]
Mit meiner offline Lösung ist sofort wieder alles OK,
obwohl die lokalen Stimmen eher schrott sind
und ja Thorsten ist auch Müll und nuschelt….
UPDATE – 2:
Meine aktuelle Konfiguration & klare Empfehlung
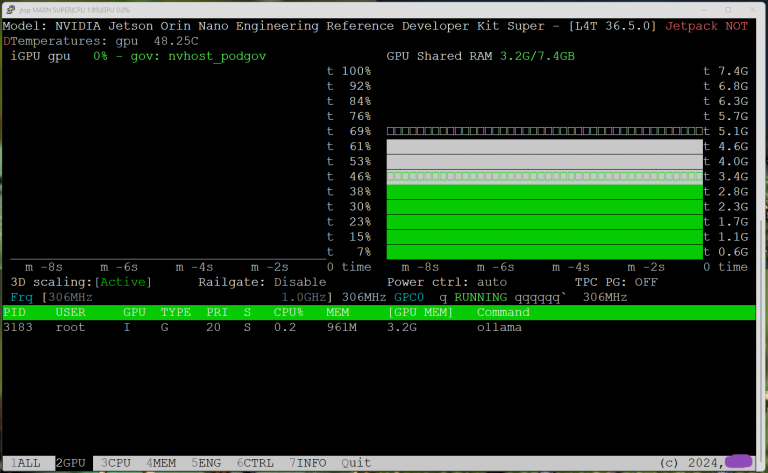
…ist die Verwendung des ‚Ternary-Bonsai-8B-gguf‘ Wie man auf dem Screenshot gut sehen kann verbraucht es sogar weniger Recourcen als mein altes Llama 3.2:3b und das für ein 8B Modell, welches normalerweise den VRAM sprengen würde
Hier ist der Hugging Face-Link für das 1.58Bit Modell: (https://huggingface.co/prism-ml/Ternary-Bonsai-8B-gguf/)
Der einzige Wermutstropfen bei der Sache ist, dass es die Installation von Lama.cpp, zum laden des Modells, erfordert.
Womit das Ternary-Bonsai-8B dann auch nicht in einem Doker Container läuft.
Doch das Ergebnis ist den Aufwand wert…
Hier ist meine aktuelle Startkonfiguration, für alle die kein TTS+STT auf dem Jetson wollen/brauchen:
#!/bin/bash
echo „— Starte KI-System Vorbereitung (Ollama Edition) —„
# 1. Desktop stoppen und RAM leeren (Essentiell für Orin Nano 8GB)
systemctl stop gdm || systemctl stop gdm3
sync && echo 3 | tee /proc/sys/vm/drop_caches
echo „RAM wurde optimiert.“
# 2. Alte Container aufräumen
echo „Bereinige alte Container…“
docker rm -f ollama-jetson open-webui 2>/dev/null
echo „— Starte Ollama Server (Optimiert für Home Assistant) —„
# 3. Ollama mit NUM_PARALLEL=2 für Stabilität bei vielen Automatisierungen
docker run -d \
–name ollama-jetson \
–runtime nvidia \
–network host \
-v ollama_data:/root/.ollama \
# Nur eine Instanz vorhalten, nicht mehr 2 !!
-e OLLAMA_NUM_PARALLEL=1 \
-e OLLAMA_KEEP_ALIVE=-1 \
-e OLLAMA_HOST=0.0.0.0:11434 \
-e OLLAMA_ORIGINS=“*“ \
ollama/ollama:latest
echo „Warte 15 Sekunden auf Initialisierung…“
sleep 15
# 4. Das Modell vorladen (Damit BrainBug sofort bereit ist)
echo „Lade Modell Llama 3.2 in den VRAM…“
# Hier ist das -d entfernen und der Text geändert
docker exec ollama-jetson ollama run llama3.2:3b „Antworte nur mit einem Punkt.“
# 5. WebUI Sektion (DEAKTIVIERT – Zeilen mit # am Anfang werden ignoriert)
# echo „— Starte Open WebUI —“
# docker run -d –name open-webui –network=host \
# -e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
# –add-host=host.docker.internal:host-gateway \
# ghcr.io/open-webui/open-webui:main
echo „— FERTIG —„
echo „Ollama läuft mit NUM_PARALLEL=2. WebUI bleibt entladen.“
echo „Nutze ‚docker logs -f ollama-jetson‘ um den Status zu sehen.“
Aus aktuellem Anlass:
Da sich durch die ‚Updateflut‘ von HA seit einigen Wochen alles was an TTS & STT über HA Cloud läuft, permanent verschlechtert, habe ich mich dazu entschlossen meinen Jetson Nano diese Funktion ebenfalls erfüllen zu lassen!
Und ja, das geht, weil in meiner Konfiguration TTS und STT, nur über die CPU und nicht im VRAM laufen!
Wer mag kann sich meine vorletzte Version hier unten ansehen und selber ausprobieren.
(meine aktuelle Version enthält noch einige systemspezifische Besonderheiten für HA die hier zu weit führen würden)
#!/bin/bash
echo „— Starte KI-System Vorbereitung (Jetson Orin Nano 8GB) —„
# 1. Desktop stoppen und RAM leeren
systemctl stop gdm || systemctl stop gdm3
sync && echo 3 | tee /proc/sys/vm/drop_caches
echo „RAM wurde optimiert.“
# 2. Alte Container aufräumen
echo „Bereinige Instanzen…“
docker rm -f ollama-jetson GG-Whisper GG-Piper 2>/dev/null
echo „— Starte Ollama Server —„
# 3. Ollama Start (Optimiert für 8GB VRAM)
docker run -d \
–name ollama-jetson \
–runtime nvidia \
–network host \
-v ollama_data:/root/.ollama \
-e OLLAMA_NUM_PARALLEL=1 \
-e OLLAMA_KEEP_ALIVE=-1 \
-e OLLAMA_HOST=0.0.0.0:11434 \
-e OLLAMA_ORIGINS=“*“ \
ollama/ollama:latest
echo „Starte GG-Whisper (STT) auf Port 10300…“
# 4. Whisper (STT) auf CPU mit eindeutigem Namen für HA
docker run -d \
–name GG-Whisper \
–network host \
–restart unless-stopped \
-v wyoming-whisper-gg-data:/data \
rhasspy/wyoming-whisper:latest \
–model base \
–language de \
–uri tcp://0.0.0.0:10300
echo „— Starte GG-Piper auf Port 10200…“
# 5. Piper mit eindeutigem Namen für HA
docker run -d \
–name GG-Piper \
–network host \
–restart unless-stopped \
-v wyoming-piper-gg-data:/data \
rhasspy/wyoming-piper:latest \
–voice de_DE-thorsten-high \
–uri tcp://0.0.0.0:10200
echo „Warte 15 Sekunden auf Initialisierung…“
sleep 15
# 6. Modell vorladen
echo „Lade Modell Llama 3.2 in den VRAM…“
docker exec -d ollama-jetson ollama run llama3.2:3b „Hallo, ich bin jetzt fertig mit laden“
echo „— FERTIG —„
echo „Ollama: 11434 | Whisper: 10300 | Piper: 10200“
echo „Nutze ‚docker logs -f ollama-jetson‘ oder ‚docker ps‘ zur Kontrolle.“